Some days into the project Lambda added Node 4.3 support. Previously the only supported Node version was 0.10 and the lack of generators made the code super messy. Without Node 4.3 this blogpost probably would look kinda different.
Lambda is not a web server!
The signature of a Lambda function:
1 2 | |
Lambda functions can be triggered from different sources (S3, DynamoDB, Scheduled Events and more). For processing HTTP requests another service is needed: API Gateway.
API Gateway is not tied to Lambda and can be used for various kinds of backends. Bottom line: The API Gateway/Lambda stack has very little to do with something like Express. On the contrary, mastering API Gateway is hard and I underestimated that. As a matter of fact, most debugging and cursing happened on API Gateway side and not because of Lambda.
How to get requests into Lambda
API Gateway provides a graphical interface where you (basically) setup an endpoint and method and map it to a Lambda function.
By default API Gateway only passes the request payload (in case of a POST/PUT) to the event parameter (see above) of a Lambda function. And for a GET request nothing is passed!
Input mapping
In order to get all the request meta data into Lambda (like path, method, ip, headers etc.) an input “Body Mapping Templates” must be set up. This is the mapping I used:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
These values are then available in the event parameter of the Lambda handler function.
How to get responses out of Lambda
For a success response it’s quite easy. From Lambda do:
1 2 3 4 5 6 | |
response is what your user will receive as the response payload.
How to setup non-default (200) responses
Probably the most annoying thing with API Gateway (and the thing that produces the most Lambda related issue in the API Gateway forums) is how to setup custom HTTP response codes. It works by regex’ing over the error reponse from Lambda.
Suppose you want to respond with a 404. From Lambda you call:
1 2 3 4 5 | |
Since the first parameter of the callback function is used, API Gateway understands it as an error. In API Gateway you setup a “Lambda Error Regex” with regex .*404.* and the user will receive status code 404.
So how to not only set the correct status code but also pass a response to the client? You can pass the status code and response body as separate properties:
1 2 3 4 5 6 7 8 9 10 | |
In API Gateway I then setup a “Lambda Error Regex” where the regex is .*\"status\":403.* and the following output “Body Mapping Template” (“Body Mapping Template” maps the reponse from Lambda to the response body that is passed to the user from API Gateway):
1 2 | |
$.errorMessage is the error data coming from Lambda.
This needs be done for all response codes. You’ll end up with something like this:

How to set response headers
Suppose you want to set a set-cookie or a location header. How to do that? You can set “Header Mappings” where you map a property from the Lambda response object to a header set in API Gateway.
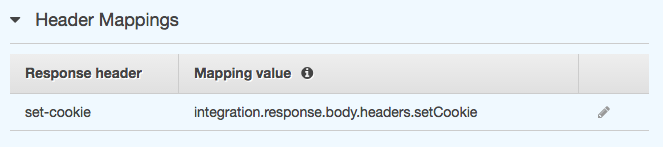
Here is the catch: that does only work with the default response (see 200 from above) but not with the “Lambda Error Regex” workaround since the “Header Mapping” can not access the $.errorMessage property.
That means that you can currently only have one response code (the one that you defined as default) to set headers. I’m sure AWS is currently working on that. Because this is bad.
Get used to swagger config file early
While the graphical user interface of API Gateway is fine at the beginning when starting to work with and understanding API Gateway, it gets super annoying down the road because you are ending up copy-pasting stuff all the time. For instance you will likely want to have the same “Lambda Error Regex” for most of your endpoints. And you definitely need to have the input “Body Mapping Templates” from above on every endpoint.
I resisted way too long against using a swagger config file, since I was unfamiliar with it and thought I already need to learn enough new stuff. However, it’s easy to understand since it provides the same settings as the graphical user interface. I suggest you set up your basic settings with the GUI and then export it via “Stages” –> “Your stage name” –> “Export” –> “Export as Swagger + API Gateway Extensions”.
Then you can edit the swagger config file locally and push it with:
1
| |
Serving static files
Most parts of the site were dynamic (the admin interface and the API), but there were also static ones (the homepage). API Gateway can be used to serve static content by using the “AWS Service Proxy” Integration type. With that static files can be proxied from S3.
But it’s slow! And requests count against the API Gateway throttling limits. Instead you should use subdomains for requests that should be handled by API Gateway Lambda (i.e. api.your_domain.com and admin.your_domain.com) and map the homepage (your_domain.com) to CloudFront. This is specially true since API Gateway can not server binary files (i.e. images).
Note: I did not test the API Gateway cache.
How to run Lambda functions locally?
I didn’t do it. Being able to run the tests locally was enough for me. Final tests I did on production. I understand that this would not be suitable for larger and more complex projects.
What to use for deployment?
I went with node-lambda. I haven’t really tested the alternatives. node-lambda does what I needed (deploy the function). Their ENV variables handling is nice.
At scale
If you’re expecting a lot of traffic you might want to contact AWS support to increase API Gateway and Lambda limits.
Lambda is smart in reusing the spawned Lambda nodes. So if your Lambda function executes relatively fast (~300ms, typical for API requests) and the traffic is moderate the default Lambda limit (100 concurent Lambdas) should be fine.
No gzip
:(
Conclusion
While Lambda is easy to get used to, having to proxy requests through API Gateway makes everything hard that is usually super-easy in plain node (with the help of express or friends). Now that I went through all the pain, everything seems obvious. But it was a hard process.
Still, serverless is the new cool kid on the block and I enjoyed not needing to deal with provisioning servers (and make them scale). AWS is the leader and they are actively improving Lambda and API Gateway.
I’m also very excited about zeit.co. With them you can just deploy your express app. Need to look into that soon.
]]>

'")
'")





{kind=link}